
代码实例:
1 | package com.example.androidx_branch.scalestudy |
1 |
|
代码实例:
1 | package com.example.androidx_branch.scalestudy |
1 |
|
给类标记为挂起点使用的注解是suspend。通过反射的方式我们得知,这个suspend标记的方法的返回值是Continuation。
1 | interface ApiInterFace { |
在阅读源码的时候,里面大量使用到了Type这类。那这个类是干嘛的呢?
java泛型在运行时会被擦除,我们就无法得到在编译时期的泛型信息。因此java提供了
Type,它可以让我们在运行的时候也能得到这些信息。
类型擦除是指泛型在运行的时候会去擦除泛型的类信息
接口解析过程:
1 | interface ApiInterFace { |
使用Retrofit调用create(Class
1 | final class RequestFactory { |
关于方法的注解解析都在RequestFactory.java 类完成。
Retrofit为啥要使用动态代理?
在Retrofit使用动态代理可以适配新出现的技术,比如以前使用Okhttp的时候,我们都是要创建一个Call对象,然后通过这个call对象去进行网络请求。然后现在出现了kotlin的协程,kotlin由于使用了动态代理,我们可以去通过代理创建可以搭配kolin的协程进行的网络请求。
在Retrofit的代理实现的类是继承自ServiceMethod抽象类。目前Retrofit已知的有:
classDiagram
HttpServiceMethod--|>ServiceMethod
SuspendForBody--|>HttpServiceMethod
SuspendForResponse--|>HttpServiceMethod
CallAdapted--|> HttpServiceMethod
ServiceMethod : +ServiceMethod parseAnnotations()
ServiceMethod : +T invoke()
class HttpServiceMethod{
+HttpServiceMethod parseAnnotations()
-CallAdapter createCallAdapter()
-Converter createREsponseConverter()
+ReturnT invoke()
+ReturnT adapter()
-RequestFactory requestFory
-okhttp3.Call.Factory callFactory
-Converter responseConverter
}
class CallAdapted{
-T adapter()
}
class SuspendForBody{
-T adapter()
}
class SuspendForResponse{
-T adapter()
}
结合类图在结合代码再来看下:
1 | // Retrofit.java |
loadServiceMethod(method)方法就是去创建了ServiceMethod对象,它通过Method上面的注解判断这次的请求是协程呢还是Call呢还是其他,然后通过创建出对应的ServiceMethod对象,调用这个对象的invoke方法,通过上面的类图我们可以看到只有HttpServiceMethod类实现了invoke方法。
1 | // HttpSercieMethod.java |
可以看到invoke实现其实就是去创建了OkHttpCall对象,然后调用adapter方法。通过类如可以看到实现adapter方法的类只有三个(哪三个,去看图)。
现在来看下loadServiceMethod是怎么通过注解来确定HttpServiceMethod具体是哪个对象的。
1 | ServiceMethod<?> loadServiceMethod(Method method) { |
可以看到是调用了ServiceMethod.parseAnnotations()方法获取到具体的HttpServiceMethod对象。
1 |
|
这里通过RequestFactory方法将解析完的接口上面的全部注解信息全部保存在了内 RequestFactory类里面。
然后将我们解析完成的数据交给了HttpServiceMethod的parseAnnotations方法去继续执行。
1 | static <ResponseT, ReturnT> HttpServiceMethod<ResponseT, ReturnT> parseAnnotations( |
看上面的代码可以知道,首先判断是不是协程,是的话在判断是不是需要返回Response。如果需要的话标志参数continuationWantsResponse设置为true。如果是协程的话,会给我们的注解组数里面手动添加一个SkipCallbackExecutor的新注解,用来实现跳过手动执行call的调用网络请求的方法。
从可用工厂返回一个适合ResponseBody类型的转换器。
1 | // Retrofit.java |
一个进行响应请求的适配器,他们的构造函数都需要:
然后纯协程写的方法不带Response返回类型的还会在多一个参数 fasle
现在来一个一个介绍这几个参数都是在干嘛:
他的获取方式是通过retrofit.callFactory
1 | //HttpSerciceMethod.java |
retrofit里面的callfactoty是什么时候创建的呢?
就是我们创建Retrofit对象的时候。也就是给Retrofit创建我们的OkhttpClient的时候就创建好了。
通过遍历callAdapterFactories数组,通过reruenTyped来确定返回哪个CallAdaper
1 | // HttpSerciveMethod.java |
1 |
|
1 | // Retrofit.java |
在Retrofit里面看到了这个callAdapterFactories。。。。。问题又来了 这个是啥?
在Retrofit类里面提供了两个公开方法:
addConverterFactory(Converter.Factory factory)
addCallAdapterFactory(CallAdapter.Factory factory)
看名知意:addConverterfactory():添加网络请求回来的结果解析工厂,最常用的有:
1 | addConverterFactory(GsonConverterFactory.create(new GsonBuilder().create())) |
看名知意:addCallAdapterFactory():进行网络请求。常用的有支持RxJava的:
1 | addCallAdapterFactory(RxJava2CallAdapterFactory.createAsync()) |
在上面创建callAdapter的时候传入一个叫adapterType的参数,那这个adapterType参数又是什么呢?
这个adapterType是一个Type类型,也就是说他是一个泛型对象,在HttpSermethod他的创建分为两种,一种是基于kotlin协程创建的adapterType。一种是基于最基本的adapterType。
1 | if (isKotlinSuspendFunction) { |
可以看到不是协程的话,那么adapterType就是获取我们方法返回的类型。如果是协程的话:
1 | // Utils.java |
如是是协程的话,那么就创建一个type对象,他的rawType = retrofit2.Call。
现在我们再来分析下callAdapeter对象创建的时候,在Retrofit的nextCallAdapter是怎么创建的:
1 | // Retrofit.java |
遍历callAdapterFactories数组找出那个可以执行returnType的类。这个方法的第一行就可以看出,他上来就判断returnType是不是Call.class对象。现在就知道了为什么在使用协程的时候,需要自己构建一个returnType指定他的rawType为Call.class的原因了。
1 | // DefaultCallAdapterFactory.java |
可以看到如果是协程的话,那么创建的callAdapter实际上是CallAdapter 通过匿名接口实现匿名内部类。
和callAdapter一样的设计思路。
到现在HttpServiceMethod对象已经创建完毕,现在我们继续跟进看是怎么调用的。
这里拿SuspendForBody这个HttpServiceMethod对象来举例:
1 | // HttpServiceMethod.java |
首先调用他们的父类HttpServiceMethod的invoke方法:
1 | // HttpServiceMethod |
创建Call对象。然后执行了adapt方法。adapt方法是在HttpServiceMethod的子类实现的。所以现在回到SuspendForBofy类。:
1 | // SuspendForBody.java |
第一行出现了callAdapter,这个callAdapter也就是刚才我们讲的根据根据returnType去创建对应的callAdapter。对于协程来说创建的就是一个匿名接口实现的匿名内部类。
1 | new CallAdapter<Object, Call<?>>() { |
call的获取过程现在知道了。
回到SuspendForBody的adapt方法:最后执行了kotlin写的扩展方法。执行了call的网络请求调用:
1 | // HttpServiceMethod |
关于协程里面一个请求是怎么发出去的,可以看到Retrofit对Call写了一个扩展方法,太秀了。~~~~
1 | suspend fun <T : Any> Call<T>.await(): T { |
Aop是一种编程思想,面向切面编程的编程思想。
具体实现的框架有:
| 方法 | 说明 | 原理 | 实现 | 特点 |
| APT | 注解处理器 | 在编译器通过注解采集信息,生成Java/Class文件 | ButterKnife,Glide,EventBus3 | 基于Javac,但是无法修改已经存在的代码的内部结构 |
| AspectJ | 面向切面编程 | 在编译后修改/生成指定的Class | Hugo | 功能强大,底层原理利用ASM,不够轻量 |
| Javassit/ASM | 操作class的框架 | 按照Class文件的格式,解析修改生成class | Qzone超级补丁,TInker热修复 | Javassit的java Api更易于使用,ASM性能更好 |
这个框架有几个重要的概念,JoinPoints:切入点,也就是在那个方法进行切入。Advice:切入的方式,是在这个方法之前切入还是之后切入,还是周围切入也就是之前和之后同时切入。
在Idea使用AspecJ框架流程:
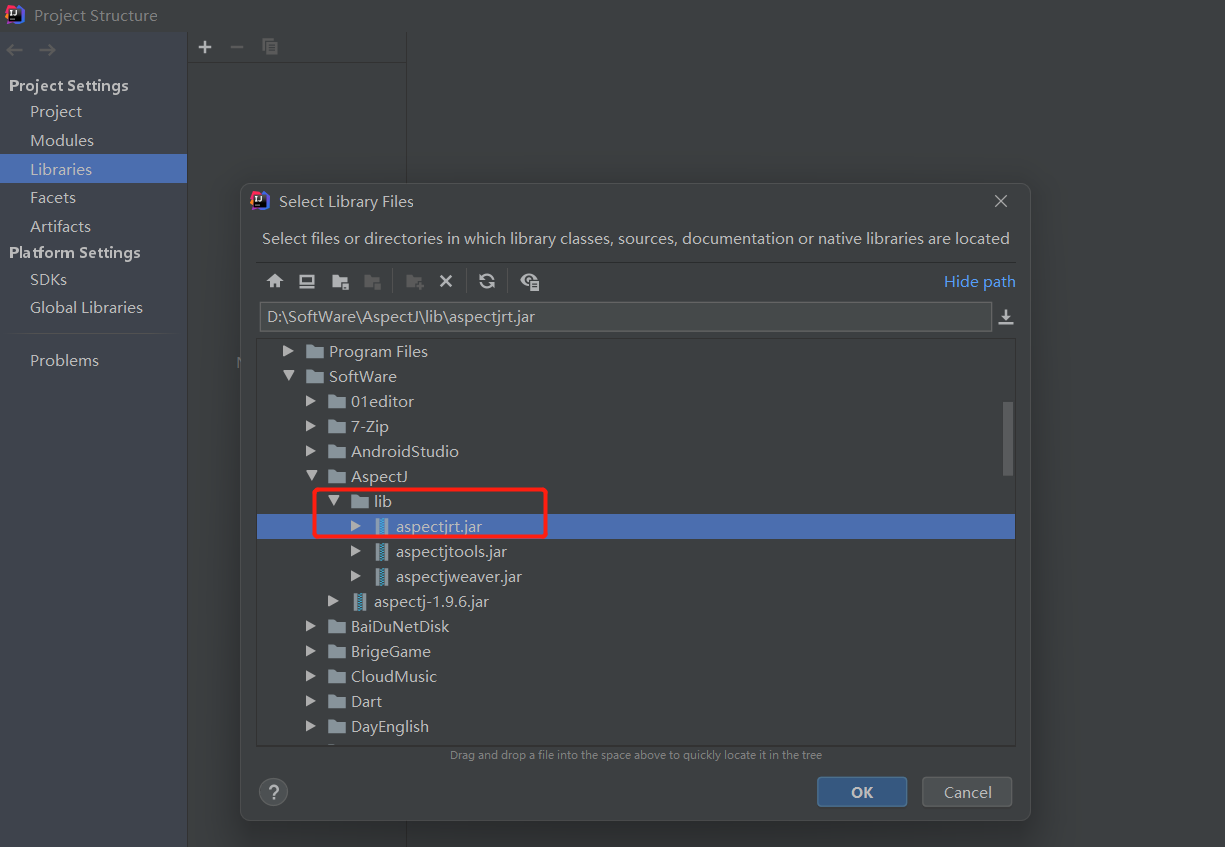
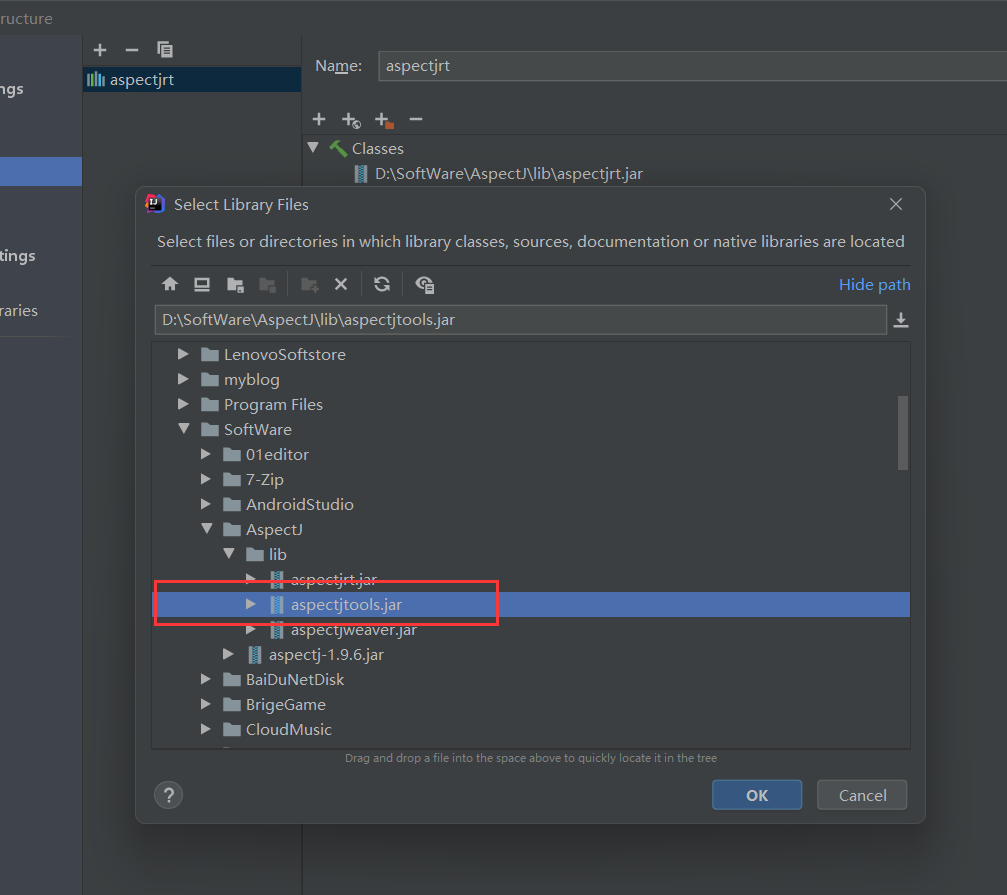
编译程序改完后我们就可以新建Aspect类:
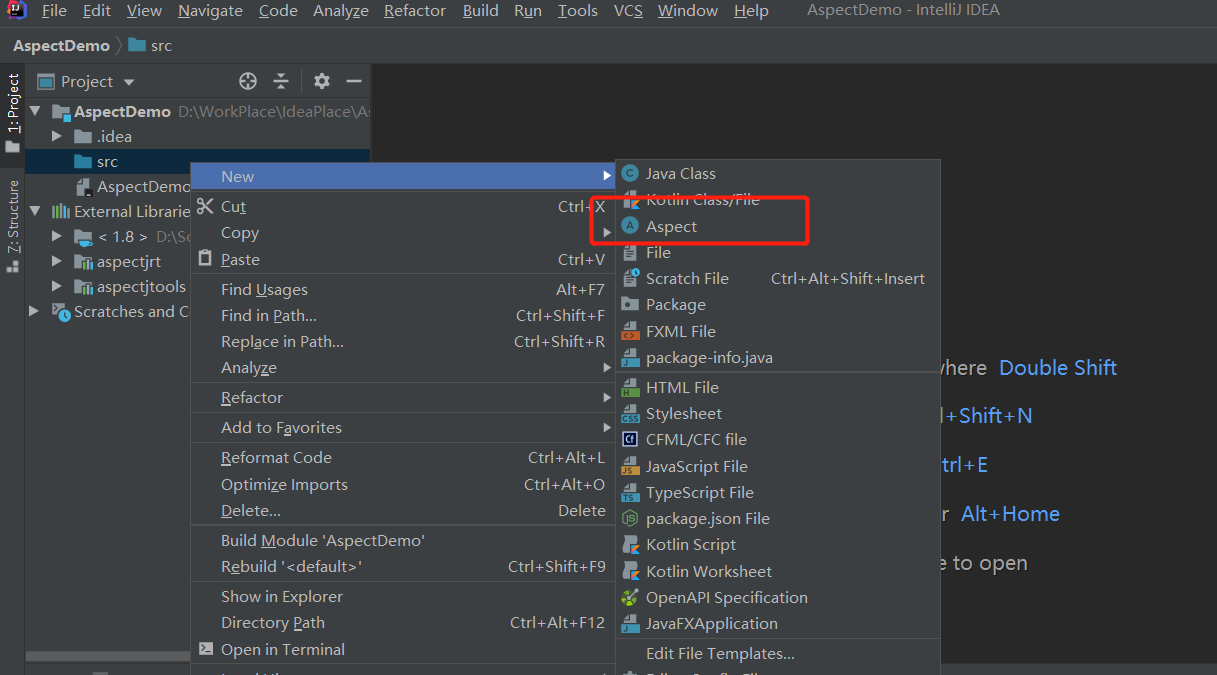
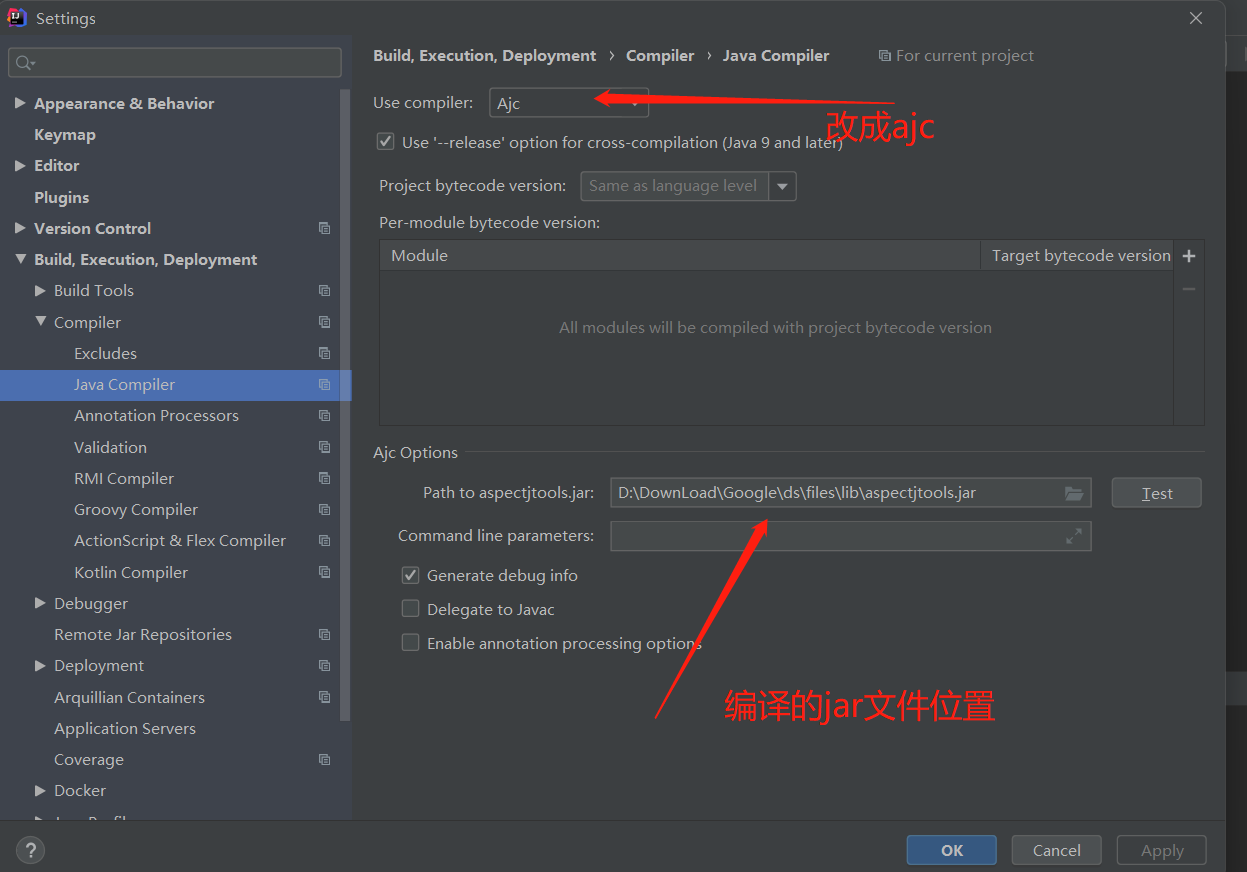
至此我们就可以使用aspectj框架了。
@Pointcut 的 12 种用法,你知道几种? - 知乎 (zhihu.com)
@Pointcut
用来指定切入点,他的作用仅仅用来帮我们定义切入点,不能在这个切入点里面写任何代码,他是搭配@Before @After @Around标签来使用的。
1 |
|
按照这个例子写我们的程序会报错:Pointcuts without an if() expression should have an empty method body
正确的写法:
1 |
|
在我们找到切入点的时候
@Before
@After
@Around
@AfterReturning
@AfterThrowing
注意这些标签都是用来帮助我们去寻找插入点 也就是 切入点
切入点的标签知道了,现在就是表达式标签了。表达式标签也就是刚才我们写在@Pointcut括号里面的那一堆东西。
| 标签 | 描述 |
| execution | 用于匹配方法执行的连接点 |
| within | 用于匹配指定类型内的方法执行 |
| this | 用于匹配当前AOP代理对象类型的执行方法,注意是AOP代理对象类型匹配,这样就可能包括引入接口*类型匹配 |
| target | 用于匹配当前目标对象类型的执行方法,注意是目标对象的类型匹配,这样就不包括引入接口类型匹配 |
| args | 用于匹配当前执行的方法传入的参数为指定类型的执行方法 |
| @within | 用于匹配所以持有指定注解类型内的方法 |
| @target | 用于匹配当前目标对象类型的执行方法,其中目标对象持有指定的注解 |
| @args | 用于匹配当前执行的方法传入的参数持有指定注解的执行 |
| @annotation | 用于匹配当前执行方法持有指定注解的方法 |
| bean | Spring AOP扩展的,AspectJ没有对于指示符,用于匹配特定名称的Bean对象的执行方法 |
1 | executation(@注解? 修饰符匹配? 返回值类型 类路径?方法名匹配 异常类型匹配?) |
案例:
| 表达式 | 描述 |
| public *.*(..) | 任何公共方法执行 |
| * com.pince..IPService.*() | com.pince包及所有子包下IPService接口中的任何任何无参方法 |
| * com.pince..*.*(...) | com.pince包及所有子包下任何类的任何方法 |
| * com.pince..IPSercice.() | com.pince包及所有子包下IPService接口的任何只有一个参数方法 |
| * com.pince..IPSercice+.*() | com.pince包及所有子包下IPService接口及子类型的任何无参方法 |
| * Service1.*(String) | 匹配Service1中只有一个参数且为String的方法 |
| * Service1.*(*,String) | 匹配Service1中只有两个参数且第二份参数为String的方法 |
| * Service1.*(..,String) | 匹配Service1中最后要给参数为String的方法 |
用法:within(类型表达式):目标对象target的类型是否和within中指定的类型匹配
匹配原则:target.getClass().equals(within表达式中指定的类型)
自我解释:只匹配对应类的数据,你不是目标类我就不会匹配上
1 | package com.javacode2018.aop.demo9.test2; |
需求1:自定义注解,然后获取被注解标记的方法的入参,注解值
1 |
|
1 | public class Service2 { |
1 |
|
1 | public class Test { |
上面这个案例可以看到我们的Service2的m3方法是有返回值的,那我们在切面里面想获取返回值可以这么修改:
1 |
|
1 -inpath: .class文件路径,可以是在jar文件中也可以是在文件目录中,路径应该包含那些AspectJ相关的文件,只有这些文件才会被AspectJ处理。输出文件会包含这些.class 。该路径就是一个单一参数,多个路径的话用分隔符隔开。
2 -classpath: 指定去哪找用户使用到的.class文件,路径可以是zip文件也可以是文件目录,该路径就是一个单一参数,多个路径的话用分隔符隔开。
3 -aspectPath: 需要被处理的切面路径,存在于jar文件或者文件目录中。在Andorid中使用的话一般指的是被@Aspect注解标示的class文件路径。需要注意的是编译版本需要与Java编译版本一致。classpath指定的路径应该包含所有的aspectpath指定的.class文件。不过默认情况下,inPath和aspectPath中的路径不一定非要放置在classPath中,因为编译器会自动处理把它们加入。路径格式与classpath和inpath样,都需要用分隔符隔开。
4 **-bootClasspath: ** 重载跟VM相关的bootClasspath,例如在Android中使用android-27的源码进行编译。路径格式与之前一样。
5 -d: 指定由AspectJ处理后的.class文件存放目录,如果不指定的话会放置在当前的工作目录中。
6 -outjar: 指定被AspectJ处理后的jar包存放的文件目录,
使用这个框架最主要就是学习如何创建我们的Models。
这个框架的设计思路就是创建Controller,Controller的作用就是用来安排我们的视图怎么展示,看他们的源码的时候在添加数据或者更新数据的时候,会调用buildModels方法。添加我们的视图模型,如果已经添加过了就不会添加到Controller的模型数组里面去。在Controller里面我们需要创建咱们的视图模型,也就是modelView,创建他的方式有三种。
From Custom Views
通过注解@ModelView
1 |
|
这个方式创建视图我还不是很懂
From DataBinding
1 | <layout xmlns:android="http://schemas.android.com/apk/res/android"> |
然后我们只需要随便创建一个文件,然后使用注解 @EpoxyDataBindingLayouts
From ViewHolders
1 |
|
Android是基于消息机制来运行的. 在 主线程也就是 ActivityThread 里,会给当前线程创建Looper,MessageQueue对象, 而 Handler也只是一个处理者.
消息类型分为:
同步屏障有什么作用,作用就是让异步任务尽快被执行.在 Android里面被最直观的运用就是调用 requestLayout,在调用这个方法的时候,会先添加一个同步屏障,然后扔进去了一个异步任务用于
了解消息机制的原理,你还可以进行卡顿分析,这是如何做到的. 在ActivtiyThead里面,处理一个消息前会打印 <<<< 这个内容, 然后在消息处理结束会打印 >>>>> ,这个时候,你就可以通过监测两个打印的相差时间就能计算一个消息运行了多久了.
准备工作:首先新建一个插件模块 plugin_module
把plugin_module里面的文件全部删了只留下src/main 和 build.gradle 文件。
1 | apply plugin: 'groovy' //必须 |
1 | // 打包的数据 插件 |
新建文件resources/META-INF/gradle-plugins
创建文件 releaseinfo.properties 。这里需要注意这个文件名字就是我们以后通过apply pligun:”这里需要写入的插件名字”。
文件内容:
1 | implementation-class=ReleaseInfoPlugin // 插件类 |
至此准备工作做好了!
在我们的插件模块的build.gradle加入以下代码:
1 | apply plugin: 'groovy' //必须 |
同步完成功能,可以看到我们多了这些任务:
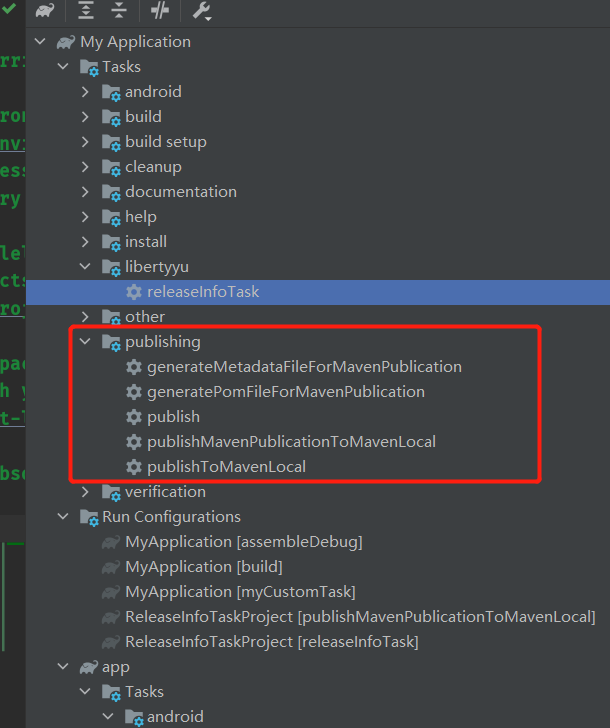
我们点击publishMaven…ToMavenLocal
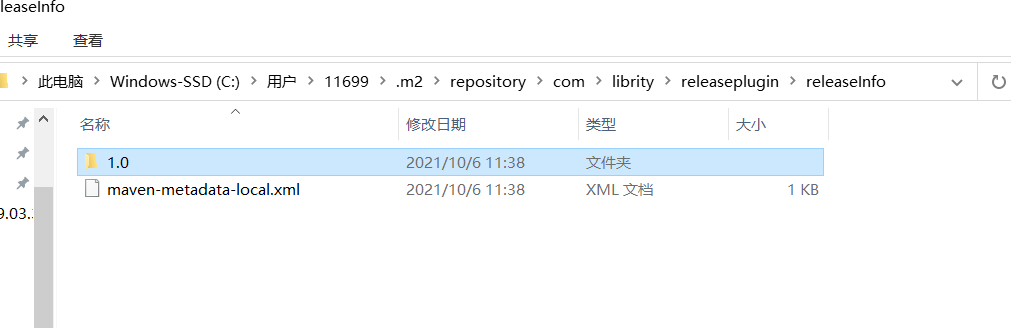
任务执行完毕后我们会在这看到我们的maven库:
在根目录的build.gradle写入:
1 | repositories { |
这些依赖写好后就可以在app的build.gradle里面进行使用了:
1 | plugins { |
1 | apply plugin: 'groovy' //必须 |
在gradle.properties里面加上这几个参数:
1 | mavenPath = .. |
同步下工程:
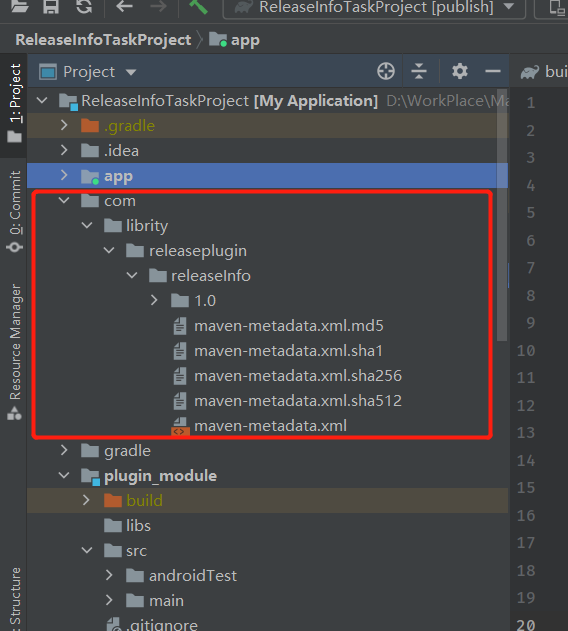
然后我们把我们的工程上传到github上面。
1 | maven{ |
然后在我们要使用的module的build.gradle
1 | plugins { |
####需求:为每次打包生成内容数据信息
Gradle自定义插件有三种方式:https://zhuanlan.zhihu.com/p/158588813
1. 在build.gradle
直接在app目录下的build.gradle文件中写
1 | class MyPlugin implements Plugin<Project>{ |
然后在
app的build.gradle文件中引入插件:
apply plugin: MyPlugin
然后再控制台输入gradlew mytask
1 | > Configure project :app |
使用这种方式可以很快的创建一个插件,缺点就是只能在当前的build.gradle使用,复用差。
2. 在buildSrc文件夹下
buildSrc是Gradle中的默认插件目录,编译的时候Gradle会自动识别这个目录,将其内的代码编译撑成插件。
在根目录新建一个文件叫buildSrc,然后在buildSrc文件新建build.gralde文件写入代码:
1 | apply(plugin = "kotlin") |
build.gradle文件内容写完后我们同步下功能,就可以在buildSrc文件里面看到文件.gradle和build这两个文件。现在我们在buildSrc下面新建文件src/main/groovy 和 src/main/resources/META-INF/gradle-plugins。
然后在groovy文件加里新建我们的插件MyPlugin.groovy
1 | class MyPlugin implements Plugin<Project> { |
写完插件怎么让编译器知道这是我们的插件呢?
然后在app的build.gradle里面映入插件:
1 | apply plugin :'com.yu.releaseInfo' |
最后在控制台进行测试:
1 | > Configure project :app |
第三种上传maven
上传maven这样所有人都可以使用咱么这个项目了。
可以参考我的另外一篇博客。 Gradle上传插件到仓库
这里我们使用第二种方式,在buildSrc里面写我们的插件。
在groovy文件夹新建类 1. ReleaseInfoExtension.groovy
1 | class ReleaseInfoExtension { |
我们把我们的基础信息放在类里面。
2. 新建插件类ReleaseInfoPlugin.groocy
这个类用来创建我们的扩展参数和扩展方法,代码如下
1 | import org.gradle.api.Plugin |
然后在resources/META-INF/gradle.plugins 下新建文件 releaseinfo.properties。内容:
1 | implementation-class=ReleaseInfoPlugin |
同步下工程。
3. 在app的build.gradle引入我们的插件
apply plugin :’releaseinfo’
4. 配置打包信息
1 | releaseInfoYu { re -> |
注意我们首先要在app目录下新建一个空白文件release.xml
5. 完成写入xml的task任务
1 | import groovy.xml.MarkupBuilder |
执行我们的assembleDebug任务后可以在release.xml文件看到如下内容:
1 | <releases> |
Cheer Up!
初始化阶段
配置阶段
执行阶段
Gradle根据setting.gradle文件的配置为项目创建Project实例。
Gradle构造一个模型表示任务,并参与构建中来。增量式构建决定我们的task是否需要运行。配置阶段完成后。整个build的project以及内部的Task关系就确定了。这个阶段非常适合为项目或指定task设置所需要的配置数据。配置阶段的实质为解析每个被加入构建项目的build.gradle脚本,比如通过apply方法引入插件,为插件扩展属性进行配置等等。。。。
注意:项目的每一次构建的任何配置代码都可以被执行-即使你只运行gradle tasks。
在执行阶段,所有的task按照配置阶段规定好的顺序,一次执行。我们通常会在根据任务执行的生命周期去动态在合适的位置插入我们自己的运行期间执行的代码断。
许多生命周期方法都被定义在了Gradle 和 Project方法里面。不要害怕使用生命周期钩子,它相反就是为了给开发者使用提供方便而设计出来的。
如果我们想在Gradle特定的阶段去Hook指定的任务,那么我们需要对如何监听生命周期的回调有一些了解。
Gradle和Project对象提供了一些方法供我们使用:
生命周期监听的设置有两个方法:
1. 实现一个特定的监听接口
2. 提供一个用于在收到通知时执行的闭包。
Project提供的一些生命周期方法:
afterEvaluate(closure) , atferEvaluate(action)
beforeEvaluate(closure) , beforeEvaluate(action)
*Gradle**提供的一些生命周期方法:
afterProject(closure) , afterProject(action)
beforeProject(closure) , beforeProject(action)
buildFinished(closure) , buildFinished(action)
projectsEvaluated(closure) , projectsEvaluated(action)
projectsLoaded(closure) , projectsLoaded(action)
settingsEvaluated(closure) , settingsEvaluated(action)
addBuildListener(buildListener)
addListener(listener)
addProjectEvaluationListener(listener)
可以看到每个方法都有两个不同参数,一个接收闭包,一个接收Action作为回调。注意,一些生命周期的方法只会在合适的位置上才会发生。
beforeEvalute() 在project开始配置前调用。这个方法很容易误用,你要是直接在子模块的build.gradle中使用肯定是不会被调用的。应为project都没配置好所以也就什么事情也不会发生。这个代码块的添加只能放在父工程的build.gradle中:
1 | this.project.subprojects { sub -> |
afaterEvaluate() 是一般比较常见的一个配置,只要在project配置成功均会被调用,不论在父模块还是在子模块。
1 | project.afterEvaluate { pro-> |
设置一个project配置完成后即执行的闭包或者action。
afterPeoject在配置参数失败后传入两个参数,前者当前project,后者显示失败信息。
1 | this.getGradle().afterProject{project,projectState-> |
设置一个project配置前执行的闭包,子模块的该方法声明在root project中回调才会执行,root project的该方法声明在setting.gradle中才执行。
1 | gradle.beforeProject { p -> |
构建结束时的回调,此时所有的任务都执行完毕,一个构建结果的对象BuildResult作为参数传递给闭包。
1 | gradle.buildFinished { r -> |
所有的peoject都配置完成后的回调,此时,所有的project都配置完毕,准备开始生成task图。gradle对象作为参数传递给闭包。
1 | gradle.projectsEvaluated {gradle -> |
当setting中的所有project都创建好时执行闭包回调,gradle对象会作为参数传递给闭包。这个方法比较特殊,只有声明在适当的位置才会发生,如果这个声明周期挂接闭包声明在build.gradle文件,那么将不会发生这个事件。应为项目创建发生在初始阶段。放在setting.gradle中是可以执行的。
1 | gradle.projectsLoaded {gradle -> |
当 settings.gradle 加载并配置完毕后执行闭包回调,setting对象已经配置好并且准备开始加载构建 project。这个回调在 build.gradle 中声明也是不起作用的,在 settings.gradle 中声明是可以的。
1 | gradle.settingsEvaluated { |
前面说过设置监听还有两个方法,通过接口监听。
1 | gradle.addProjectEvaluationListener(new ProjectEvaluationListener() { |
添加一个实现来listener接口的对象到build
添加一个BuildListener对象到Build
1 | gradle.addBuildListener(new BuildListener() { |
在配置时,Gradle决定在执行阶段要运行的task顺序,他们依赖关系的内部结构被建模为一个有向无环图。我们称之为task执行图。它可以用TaskExecutionGraph来表示。可以通过gradle.taskGraph来获取。在TaskExecutationGraph中也可以设置一些Task生命周期回到。
添加 task 执行图的监听器,当执行图配置好会执行通知。
1 | gradle.taskGraph.addTaskExecutionGraphListener(new TaskExecutionGraphListener() { |
添加 task 执行监听器,当 task 执行前或者执行完毕会执行回调发出通知。
1 | gradle.taskGraph.addTaskExecutionListener(new TaskExecutionListener() { |
1 | gradle.taskGraph.afterTask { task -> |
1 | gradle.taskGraph.beforeTask { task -> |
设置一个 task 执行图准备好后的闭包或者回调方法。
该 taskGrahp 作为参数传递给闭包。
1 | gradle.taskGraph.whenReady { taskGrahp -> |
我们通过在生命周期回调中添加打印的方法来看下顺序:
1 | task hello { |
为了保证生命周期的各个回调方法都被执行,我们在 settings.gradle 中添加各个回调方法。
1 | gradle.addBuildListener(new BuildListener() { |
执行 task info
1 | ./gradlew hello |
因此,生命周期回调的执行顺序是:
非常好的博客:https://www.heqiangfly.com/2016/03/18/development-tool-gradle-lifecycle/